🖉 Approximating E3-LIN is NP-Hard
This lecture, which I gave for my 18.434 seminar, focuses on the MAX-E3LIN problem. We prove that approximating it is NP-hard by a reduction from LABEL-COVER.
1. Introducing MAX-E3LIN
In the MAX-E3LIN problem, our input is a series of linear equations in binary variables, each with three terms. Equivalently, one can think of this as variables and ternary products. The objective is to maximize the fraction of satisfied equations.
Example 1 (Example of MAX-E3LIN instance)
A diligent reader can check that we may obtain but not .
Remark 2. We immediately notice that
- If there’s a solution with value , we can find it easily with linear algebra.
- It is always possible to get at least by selecting all-zero or all-one.
The theorem we will prove today is that these “obvious” observations are essentially the best ones possible! Our main result is that improving the above constants to 51% and 99%, say, is NP-hard.
Theorem 3 (Hardness of MAX-E3LIN)
The vs. decision problem for MAX-E3LIN is NP-hard.
This means it is NP-hard to decide whether an MAX-E3LIN instance has value or (given it is one or the other). A direct corollary of this is approximating MAX-SAT is also NP-hard.
Corollary 4. The vs. decision problem for MAX-SAT is NP-hard.
Remark 5. The constant is optimal in light of a random assignment. In fact, one can replace with , but we don’t do so here.
Proof: Given an equation in MAX-E3LIN, we consider four formulas , , , . Either three or four of them are satisfied, with four occurring exactly when . One does a similar construction for .
The hardness of MAX-E3LIN is relevant to the PCP theorem: using MAX-E3LIN gadgets, Hastad was able to prove a very strong version of the PCP theorem, in which the verifier merely reads just three bits of a proof!
Theorem 6 (Hastad PCP)
Let . We have In other words, any has a (non-adaptive) verifier with the following properties.
- The verifier uses random bits, and queries just three (!) bits.
- The acceptance condition is either or .
- If , then there is a proof which is accepted with probability at least .
- If , then every proof is accepted with probability at most .
2. Label Cover
We will prove our main result by reducing from the LABEL-COVER. Recall LABEL-COVER is played as follows: we have a bipartite graph , a set of keys for vertices of and a set of labels for . For every edge there is a function specifying a key for every label . The goal is to label the graph while maximizing the number of edges with compatible key-label pairs.
Approximating LABEL-COVER is NP-hard:
Theorem 7 (Hardness of LABEL-COVER)
The vs. decision problem for LABEL-COVER is NP-hard for every , given and are sufficiently large in .
So for any , it is NP-hard to decide whether one can satisfy all edges or fewer than of them.
3. Setup
We are going to make a reduction of the following shape:
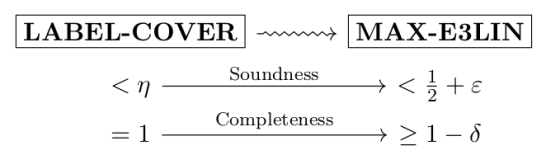
In words this means that
- “Completeness”: If the LABEL-COVER instance is completely satisfiable, then we get a solution of value in the resulting MAX-E3LIN.
- “Soundness”: If the LABEL-COVER instance has value , then we get a solution of value in the resulting MAX-E3LIN.
Thus given an oracle for MAX-E3LIN decision, we can obtain vs. decision for LABEL-COVER, which we know is hard.
The setup for this is quite involved, using a huge number of variables. Just to agree on some conventions:
Definition 8 (“Long Code”)
A -indexed binary string is a sequence indexed by . We can think of it as an element of . An -binary string is defined similarly.
Now we initialize variables:
- At every vertex , we will create binary variables, one for every -indexed binary string. It is better to collect these variables into a function
-
Similarly, at every vertex , we will create binary variables, one for every -indexed binary string, and collect these into a function
Picture:
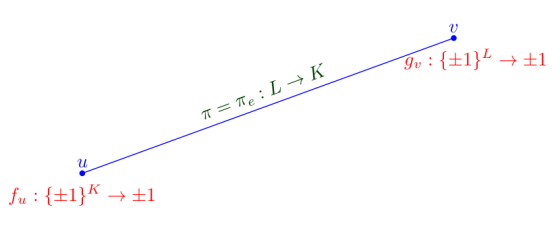
An edge in our setup.
Next we generate the equations. Here’s the motivation: we want to do this in such a way that given a satisfying labelling for LABEL-COVER, nearly all the MAX-E3LIN equations can be satisfied. One idea is as follows: for every edge , letting ,
- Take a -indexed binary string at random. Take an -indexed binary string at random.
- Define the -indexed binary string by .
- Write down the equation for the MAX-E3LIN instance.
Thus, assuming we had a valid coloring of the graph, we could let and be the dictator functions for the colorings. In that case, , , and , so the product is always .
Unfortunately, this has two fatal flaws:
- This means a instance of LABEL-COVER gives a instance of MAX-E3LIN, but we need to have a hope of working.
- Right now we could also just set all variables to be .
We fix this as follows, by using the following equations.
Definition 8 (Equations of reduction)
For every edge , with , we alter the construction and say
- Let be and be random as before.
- Let be a random -indexed binary string, drawn from a -biased distribution ( with probability ). And now define by
The represents “noise” bits, which resolve the first problem by corrupting a bit of with probability .
- Write down one of the following two equations with probability each:
This resolves the second issue.
This gives a set of equations.
I claim this reduction works. So we need to prove the “completeness” and “soundness” claims above.
4. Proof of Completeness
Given a labeling of with value , as described we simply let and be dictator functions corresponding to this valid labelling. Then as we’ve seen, we will pass of the equations.
5. A Fourier Computation
Before proving soundness, we will first need to explicitly compute the probability an equation above is satisfied. Remember we generated an equation for based on random strings , , .
For , we define
Thus maps subsets of to subsets of .
Remark 9. Note that and that if is odd.
Lemma 10 (Edge Probability)
The probability that an equation generated for is true is
Proof: Omitted for now…
6. Proof of Soundness
We will go in the reverse direction and show (constructively) that if there is MAX-E3LIN instance has a solution with value , then we can reconstruct a solution to LABEL-COVER with value . (The use of here will be clear in a moment). This process is called “decoding”.
The idea is as follows: if is a small set such that is large, then we can pick a key from at random for ; compare this with the dictator functions where and . We want to do something similar with .
Here are the concrete details. Let and be constants (the actual values arise later).
Definition 11. We say that a nonempty set of keys is heavy for if Note that there are at most heavy sets by Parseval.
Definition 12. We say that a nonempty set of labels is -excellent for if
In particular so at least one compatible key-label pair is in .
Notice that, unlike the case with , the criteria for “good” in actually depends on the edge in question! This makes it easier to keys than to select labels. In order to pick labels, we will have to choose from a distribution.
Lemma 13 (At least of are excellent)
For any edge , at least of the possible according to the distribution are -excellent.
Proof: Applying an averaging argument to the inequality
shows there is at least chance that is odd and satisfies where . In particular, . Finally by Remark 9, we see is heavy.
Now, use the following algorithm.
-
For every vertex , take the union of all heavy sets, say
Pick a random key from . Note that , since there are at most heavy sets (by Parseval) and each has at most elements.
- For every vertex , select a random set according to the distribution , and select a random element from .
I claim that this works.
Fix an edge . There is at least an chance that is -excellent. If it is, then there is at least one compatible pair in . Hence we conclude probability of success is at least
Addendum: it’s pointed out to me this isn’t right; the overall probability of the equation given by an edge is , but this doesn’t imply it for every edge. Thus one likely needs to do another averaging argument.